Tecnologias da Informação — 136 questão(ões)
#641
ME
Dif. 2
(FCC – 2019 – SANASA Campinas – Analista de Tecnologia da Informação – Análise e Desenvolvimento)
Atenção: Para responder à questão, considere a imagem abaixo.
O Processo, representado na imagem por um retângulo vertical, é um método de alimentação do Data Warehouse a partir de diversos dados da organização. Trata-se de
Atenção: Para responder à questão, considere a imagem abaixo.
O Processo, representado na imagem por um retângulo vertical, é um método de alimentação do Data Warehouse a partir de diversos dados da organização. Trata-se de
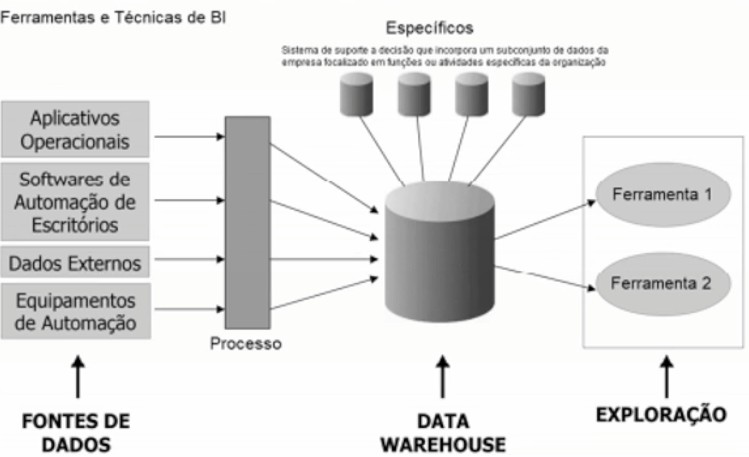
- A) ODS.
- B) ERP.
- C) ETL.
- D) CRM.
- E) EIS.
#640
ME
Dif. 2
(FCC – 2019 – SANASA Campinas – Analista de Tecnologia da Informação – Análise e Desenvolvimento)
Atenção: Para responder à questão, considere a imagem abaixo.
As ferramentas de Exploração identificadas como Ferramenta 1 e Ferramenta 2 na imagem, dentro do contexto a que se aplicam, são, dentre outras,
Atenção: Para responder à questão, considere a imagem abaixo.
As ferramentas de Exploração identificadas como Ferramenta 1 e Ferramenta 2 na imagem, dentro do contexto a que se aplicam, são, dentre outras,
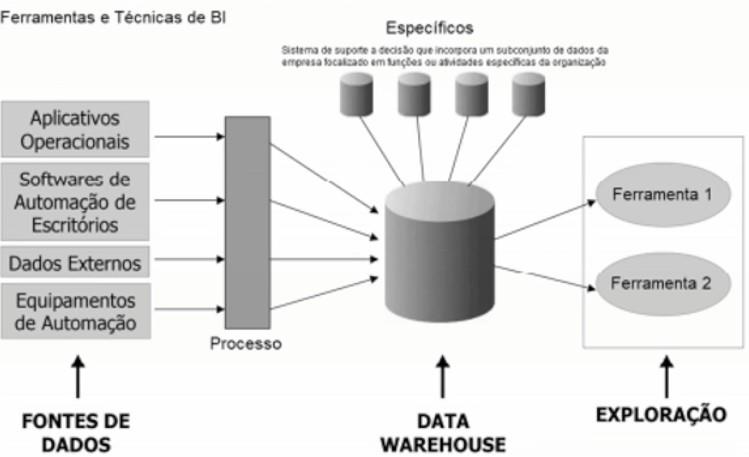
- A) Staging Area e Data Mining.
- B) OLAP e Data Mining.
- C) Snowflake e Staging Area.
- D) OLAP e Near Line Storage.
- E) Near Line Storage e Star Schema.
#639
ME
Dif. 2
(FCC – 2018 – TCE-RS – Auditor Público Externo – Administração Pública ou de Empresas) Considerando a teoria da modelagem dimensional, composta por tabelas dimensão e tabela fato, utilizada em data warehouses, assinale a alternativa correta.
- A) todas as tabelas dimensão devem possuir o mesmo número de atributos.
- B) o grau de relacionamento da tabela fato para as tabelas dimensão é de muitos para muitos.
- C) a tabela fato não deve possuir atributos do tipo numérico.
- D) não há relacionamento entre as tabelas dimensão e a tabela fato.
- E) não há limitação quanto ao número de tabelas dimensão.
#638
ME
Dif. 2
(FCC – 2018 – SEFAZ-SC – Auditor-Fiscal da Receita Estadual – Auditoria e Fiscalização) Atenção: Para responder à questão, considere o seguinte caso hipotético:
Um Auditor da Receita Estadual pretende descobrir, após denúncia, elementos que possam caracterizar e fundamentar a possível existência de fraudes, tipificadas como sonegação tributária, que vêm ocorrendo sistematicamente na arrecadação do ICMS.
A denúncia é que, frequentemente, caminhões das empresas Org1, Org2 e Org3 não são adequadamente fiscalizados nos postos de fronteiras. Inobservâncias de procedimentos podem ser avaliadas pelo curto período de permanência dos caminhões dessas empresas na operação de pesagem, em relação ao período médio registrado para demais caminhões.
Para caracterizar e fundamentar a existência de possíveis fraudes, o Auditor deverá coletar os registros diários dos postos por, pelo menos, 1 ano e elaborar demonstrativos para análises mensais, trimestrais e anuais.
O Auditor poderá fazer análises de pesagens diversas a partir de operações feitas sobre o cubo de dados multidimensional do Data Warehouse, por exemplo, trocar a ordem, ou aumentar ou diminuir a granularidade dos dados em análise, entre outras, como é o caso do uso da operação OLAP.
Considerando os conceitos de fatos e dimensões, os elementos de dados classificados como dimensões são, apenas,
Um Auditor da Receita Estadual pretende descobrir, após denúncia, elementos que possam caracterizar e fundamentar a possível existência de fraudes, tipificadas como sonegação tributária, que vêm ocorrendo sistematicamente na arrecadação do ICMS.
A denúncia é que, frequentemente, caminhões das empresas Org1, Org2 e Org3 não são adequadamente fiscalizados nos postos de fronteiras. Inobservâncias de procedimentos podem ser avaliadas pelo curto período de permanência dos caminhões dessas empresas na operação de pesagem, em relação ao período médio registrado para demais caminhões.
Para caracterizar e fundamentar a existência de possíveis fraudes, o Auditor deverá coletar os registros diários dos postos por, pelo menos, 1 ano e elaborar demonstrativos para análises mensais, trimestrais e anuais.
O Auditor poderá fazer análises de pesagens diversas a partir de operações feitas sobre o cubo de dados multidimensional do Data Warehouse, por exemplo, trocar a ordem, ou aumentar ou diminuir a granularidade dos dados em análise, entre outras, como é o caso do uso da operação OLAP.
Considerando os conceitos de fatos e dimensões, os elementos de dados classificados como dimensões são, apenas,
- A) identificação do posto, data da pesagem e tempo de permanência.
- B) empresa, data da pesagem e tempo de permanência.
- C) identificação do posto e empresa.
- D) identificação do posto, empresa e data da pesagem.
- E) empresa e data da pesagem.
#634
ME
Dif. 2
(CESPE – 2014 – ANATEL – Analista Administrativo – Desenvolvimento de Sistemas) No que se refere a banco de dados distribuído, programação distribuída, desenvolvimento em nuvem e processamento em GRID, julgue os itens que se seguem.
No Hadoop MapReduce, o JobTracker é o processo-escravo responsável por aceitar submissões de tarefas e disponibilizar funções administrativas.
No Hadoop MapReduce, o JobTracker é o processo-escravo responsável por aceitar submissões de tarefas e disponibilizar funções administrativas.
- A) Certo
- B) Errado
#633
ME
Dif. 2
(CESPE / CEBRASPE – 2021 – SERPRO – Analista – Especialização: Ciência de Dados) Sobre processamento de dados, julgue o item que se segue.
MapReduce divide o conjunto de dados de entrada em blocos independentes que são processados pelas tarefas de mapa de uma maneira completamente paralela. Essa estrutura classifica as saídas dos mapas, as quais são, então, inseridas nas tarefas de redução.
MapReduce divide o conjunto de dados de entrada em blocos independentes que são processados pelas tarefas de mapa de uma maneira completamente paralela. Essa estrutura classifica as saídas dos mapas, as quais são, então, inseridas nas tarefas de redução.
- A) Certo
- B) Errado
#632
ME
Dif. 2
(CESPE – 2018 – Polícia Federal – Papiloscopista Policial Federal) Julgue o item seguinte, a respeito de big data e tecnologias relacionadas a esse conceito.
MapReduce oferece um modelo de programação com processamento por meio de uma combinação entre chaves e valores.
MapReduce oferece um modelo de programação com processamento por meio de uma combinação entre chaves e valores.
- A) Certo
- B) Errado
#631
ME
Dif. 2
(CESPE / CEBRASPE – 2022 – SECONT-ES – Auditor do Estado – Tecnologia da Informação) Julgue o item a seguir, relativo ao processamento MapReduce.
A implementação do MapReduce é responsável por quebrar os dados em pedaços, criar várias instâncias das funções map e reduce, alocá-las e ativá-las em máquinas disponíveis na infraestrutura física, além de monitorar os cálculos para eventuais falhas.
A implementação do MapReduce é responsável por quebrar os dados em pedaços, criar várias instâncias das funções map e reduce, alocá-las e ativá-las em máquinas disponíveis na infraestrutura física, além de monitorar os cálculos para eventuais falhas.
- A) Certo
- B) Errado
#630
ME
Dif. 2
(CESPE / CEBRASPE – 2022 – MC – Técnico em Complexidade Gerencial – Cargo 1) Acerca de processamento MapReduce, julgue o item a seguir.
MapReduce é um modelo de programação desenhado para processar grandes volumes de dados em paralelo, dividindo o trabalho em um conjunto de tarefas independentes.
MapReduce é um modelo de programação desenhado para processar grandes volumes de dados em paralelo, dividindo o trabalho em um conjunto de tarefas independentes.
- A) Certo
- B) Errado
#629
ME
Dif. 2
(FGV – 2015 – TJ-PI – Analista Judiciário – Analista de Sistemas / Banco de Dados)
Bancos de dados conhecidos como NoSQL podem ser particionados em diferentes servidores, o que introduz o problema de processar consultas que envolvem múltiplos nós de processamento. Um modelo usualmente empregado nessas circunstâncias é conhecido como:
Bancos de dados conhecidos como NoSQL podem ser particionados em diferentes servidores, o que introduz o problema de processar consultas que envolvem múltiplos nós de processamento. Um modelo usualmente empregado nessas circunstâncias é conhecido como:
- A) CAP Theorem;
- B) Map/Reduce;
- C) Hash tables;
- D) Clustered columns;
- E) Data Thread.
#628
ME
Dif. 2
(CESPE / CEBRASPE – 2021 – SERPRO – Analista – Especialização: Ciência de Dados) Considerando o projeto Apache Hadoop, julgue o item subsequente.
Ao serem armazenados no HDFS (Hadoop Distributed File System), os dados do Hadoop são divididos em blocos e distribuídos em discos distintos de um mesmo servidor, o que acelera o seu processamento, já que são pesquisados de forma simultânea, e não de forma sequencial.
Ao serem armazenados no HDFS (Hadoop Distributed File System), os dados do Hadoop são divididos em blocos e distribuídos em discos distintos de um mesmo servidor, o que acelera o seu processamento, já que são pesquisados de forma simultânea, e não de forma sequencial.
- A) Certo.
- B) Errado.
#627
ME
Dif. 2
(INSTITUTO AOCP – 2020 – MJSP – Engenheiro de Dados – Big Data) O HDFS é o sistema de arquivos do Hadoop. Ele possui uma arquitetura mestre-escravo na qual um servidor é responsável por fazer todo o gerenciamento de metadados do sistema. Dentro da arquitetura do Hadoop, como se denomina esse servidor?
- A) NameNode.
- B) DataNode.
- C) HDFSnode.
- D) LinkNode.
- E) TraceNode.
#626
ME
Dif. 2
(FGV – 2023 – SEFAZ-MG – Auditor Fiscal da Receita Estadual – Tecnologia da Informação (Tarde))
O principal objetivo do Hadoop YARN foi dividir as funcionalidades de gerenciamento de recursos e agendamento/monitoramento de tarefas em daemons separados.
Assinale a opção que não figura como uma característica da arquitetura do Hadoop YARN.
O principal objetivo do Hadoop YARN foi dividir as funcionalidades de gerenciamento de recursos e agendamento/monitoramento de tarefas em daemons separados.
Assinale a opção que não figura como uma característica da arquitetura do Hadoop YARN.
- A) O ResourceManager é a autoridade máxima que arbitra os recursos entre todas as aplicações do sistema e possui dois componentes principais: Scheduler e ApplicationsManager.
- B) O Scheduler é responsável por alocar recursos para as aplicações em execução e está sujeito a restrições de capacidade de recursos, filas etc.
- C) O Scheduler é um scheduler puro no sentido de que não realiza nenhuma ação de monitoramento ou tracking de status para o aplicativo.
- D) O NodeManager é o agente deployado em cada máquina e não é responsável pelo monitoramento de recursos (CPU, memória, disco, rede).
- E) O ApplicationManager é responsável por aceitar envios de jobs, negociar o primeiro container para executar a instância ApplicationMaster para a aplicação e fornecer o serviço para reiniciar o container ApplicationMaster em caso de falha.
#625
ME
Dif. 2
(CESPE / CEBRASPE - 2021 - SERPRO) Considerando o projeto Apache Hadoop, julgue os itens subsequentes.
Um projeto relacionado ao Hadoop e mantido pela Apache é o Hive, que é uma camada de data warehouse que roda em cima do Hadoop e que utiliza uma linguagem similar à SQL, denominada Hive SQL.
Um projeto relacionado ao Hadoop e mantido pela Apache é o Hive, que é uma camada de data warehouse que roda em cima do Hadoop e que utiliza uma linguagem similar à SQL, denominada Hive SQL.
- A) Certo.
- B) Errado.
#624
ME
Dif. 2
(CESPE / CEBRASPE - 2021 - SERPRO - Analista - Especialização: Ciência de Dados) Considerando o projeto Apache Hadoop, julgue os itens subsequentes.
O subprojeto Sqoop atua na camada funcional de data warehouse e queries do Hadoop.
O subprojeto Sqoop atua na camada funcional de data warehouse e queries do Hadoop.
- A) Certo.
- B) Errado.
#623
ME
Dif. 2
(Instituto Consulplan - 2023 - SEGER-ES - Analista do Executivo - Tecnologia da Informação) O processamento em batch tem grande eficiência; é altamente escalável, de baixo custo e processa dados em repouso. Assinale, a seguir, os três componentes essenciais de uma arquitetura em batch (Hadoop).
- A) Kafka; Spark; e Flink.
- B) YARN; Spark; e Kafka.
- C) HDFS; Kafka; e Akka Streams.
- D) Flink; MapReduce; e Akka Streams.
- E) HDFS; MapReduce e/ou Spark; e YARN.
#622
ME
Dif. 2
(FGV - 2022 - SEFAZ-AM - Analista de Tecnologia da Informação da Fazenda Estadual)
Com relação às características dos componentes do ecossistema Hadoop, analise as afirmativas a seguir.
I. Kafka é um gerenciador de armazenamento de dados do tipo colunar de código aberto de fácil integração com MapReduce e Spark, que utiliza o modelo de consistência forte, permite que o desenvolvedor escolha requisitos de consistência por solicitação, incluindo a opção de consistência estritamente serializável.
II. Impala, que tem forte integração com o Kudu, permite que o desenvolvedor de aplicações o utilize para inserir, consultar, atualizar e excluir dados no Kudu usando a sintaxe SQL do Impala. Adicionalmente, permite usar JDBC ou ODBC para conectar aplicativos novos ou pré-existentes escritos em qualquer linguagem, estrutura ou ferramenta de inteligência de negócios.
III. Kudu permite integrar seu próprio catálogo com o Hive Metastore (HMS). O HMS é o provedor de metadados e catálogo padrão no ecossistema Hadoop. Quando a integração está habilitada, as tabelas Kudu podem ser descobertas e usadas por ferramentas externas com reconhecimento de HMS, mesmo que elas não estejam integradas ao Kudu.
Está correto o que se afirma em
Com relação às características dos componentes do ecossistema Hadoop, analise as afirmativas a seguir.
I. Kafka é um gerenciador de armazenamento de dados do tipo colunar de código aberto de fácil integração com MapReduce e Spark, que utiliza o modelo de consistência forte, permite que o desenvolvedor escolha requisitos de consistência por solicitação, incluindo a opção de consistência estritamente serializável.
II. Impala, que tem forte integração com o Kudu, permite que o desenvolvedor de aplicações o utilize para inserir, consultar, atualizar e excluir dados no Kudu usando a sintaxe SQL do Impala. Adicionalmente, permite usar JDBC ou ODBC para conectar aplicativos novos ou pré-existentes escritos em qualquer linguagem, estrutura ou ferramenta de inteligência de negócios.
III. Kudu permite integrar seu próprio catálogo com o Hive Metastore (HMS). O HMS é o provedor de metadados e catálogo padrão no ecossistema Hadoop. Quando a integração está habilitada, as tabelas Kudu podem ser descobertas e usadas por ferramentas externas com reconhecimento de HMS, mesmo que elas não estejam integradas ao Kudu.
Está correto o que se afirma em
- A) I, apenas.
- B) II, apenas.
- C) III, apenas.
- D) I e II, apenas.
- E) II e III, apenas.
#621
ME
Dif. 2
(Instituto Consulplan - 2023 - SEGER-ES - Analista do Executivo - Tecnologia da Informação) Dados massivos são grandes grupos de dados que podem ser capturados, comunicados, agregados, armazenados e analisados. Uma das plataformas de processamento de dados massivos mais conhecidas é o Apache Hadoop. Sobre tal plataforma, assinale a afirmativa correta.
- A) Trata-se da implementação mais popular, de código aberto, do MapReduce.
- B) É a solução mais adequada para o processamento de arquivos pequenos.
- C) Refere-se a uma plataforma verticalmente escalável e não tolerante a falhas, mas muito utilizada para processamento massivo de dados.
- D) Sua maior desvantagem é o fato de não possibilitar a utilização de máquinas e rede convencionais para realizar o processamento da sua massa de dados.
- E) Somente permite a execução de aplicações desde que seja implantado seu próprio aglomerado de máquinas, ou seja, não permite a utilização de serviços em nuvem.
#620
ME
Dif. 2
(ESAF - 2016 - ANAC - Analista Administrativo - Área 2) Para o processamento de grandes massas de dados, no contexto de Big Data, é muito utilizada uma plataforma de software em Java, de computação distribuída, voltada para clusters, inspirada no MapReduce e no GoogleFS. Esta plataforma é o(a):
- A) Yam Common.
- B) GoogleCrush.
- C) EMRx.
- D) Hadoop.
- E) MapFix.
#619
ME
Dif. 2
(CESGRANRIO - 2021 - Banco do Brasil - Agente de Tecnologia) Com o grande crescimento da massa de dados (big data), as empresas adotaram soluções de armazenamento (storage) de alto desempenho. A técnica de storage na qual uma rede de dados é dedicada a fornecer o acesso aos blocos de dados dos arrays de discos, de forma transparente para o sistema operacional como dispositivos localmente plugados, é chamada de:
- A) Storage Area Network - SAN
- B) Network Attached Storage - NAS
- C) Common Internet File System - CIFS
- D) Network File System - NFS
- E) Shared File System - SFS